


In today's world of cloud computing, it is often necessary to process and transform large amounts of data in real-time. AWS Lambda is a service that allows you to run code in response to events. Such as uploading an object to an Amazon S3 bucket or requests to the Amazon API Gateway. In this blog post, we will discuss how you can use AWS Lambda to efficiently transform S3 objects as they are uploaded. Allowing you to process and analyze your data more effectively.
By using AWS Lambda, you can save time and resources compared to traditional batch processing. Your code is only executed when an object is uploaded to S3. It scales automatically to meet your application's demands. This can help you process and analyze your data faster and more efficiently. Without worrying about managing infrastructure.
Next, we will walk through the setup of this integration and how to transform the S3 objects with Lambda. You can trigger Lambda from different cloud-native services. We are looking at how to get data uploaded to S3 and transform the directory structure of the S3 bucket.
In our example, we are taking uploaded GuardDuty alerts in an S3 bucket and ordering them by type. The type of GuardDuty alert is giving more information about the threat: ThreatPurpose:ResourceTypeAffected/ThreatFamilyName.DetectionMechanism!Artifact. The folder structure before the transformation looks like this:
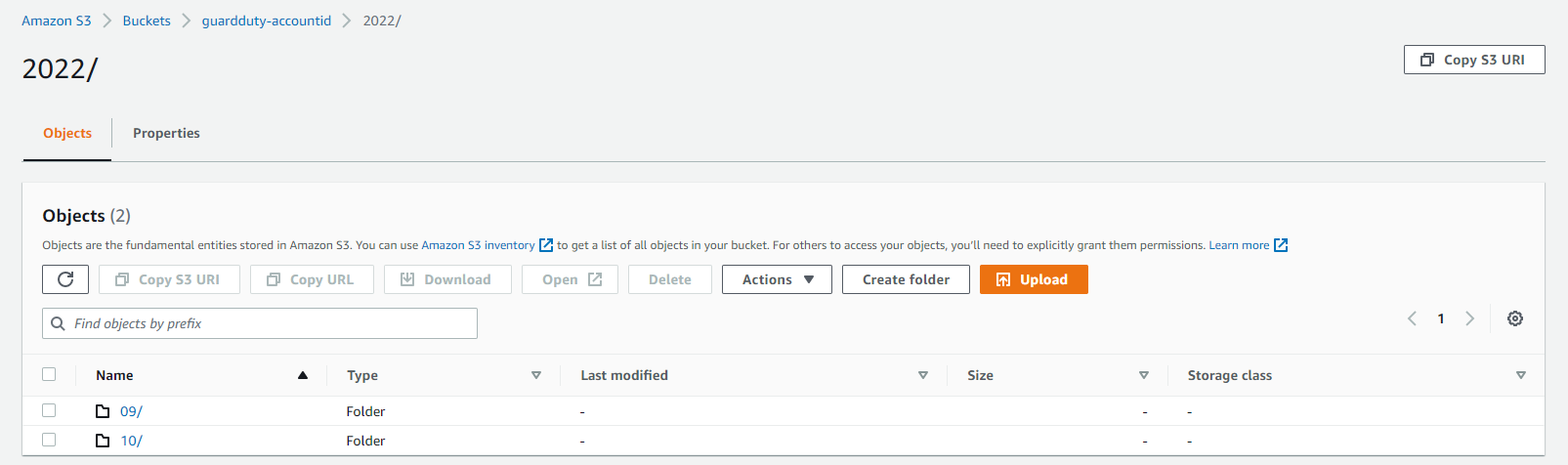
The GuardDuty alerts in the S3 bucket are ordered by date.
After we have created the lambda function, the folder structure will look like this:
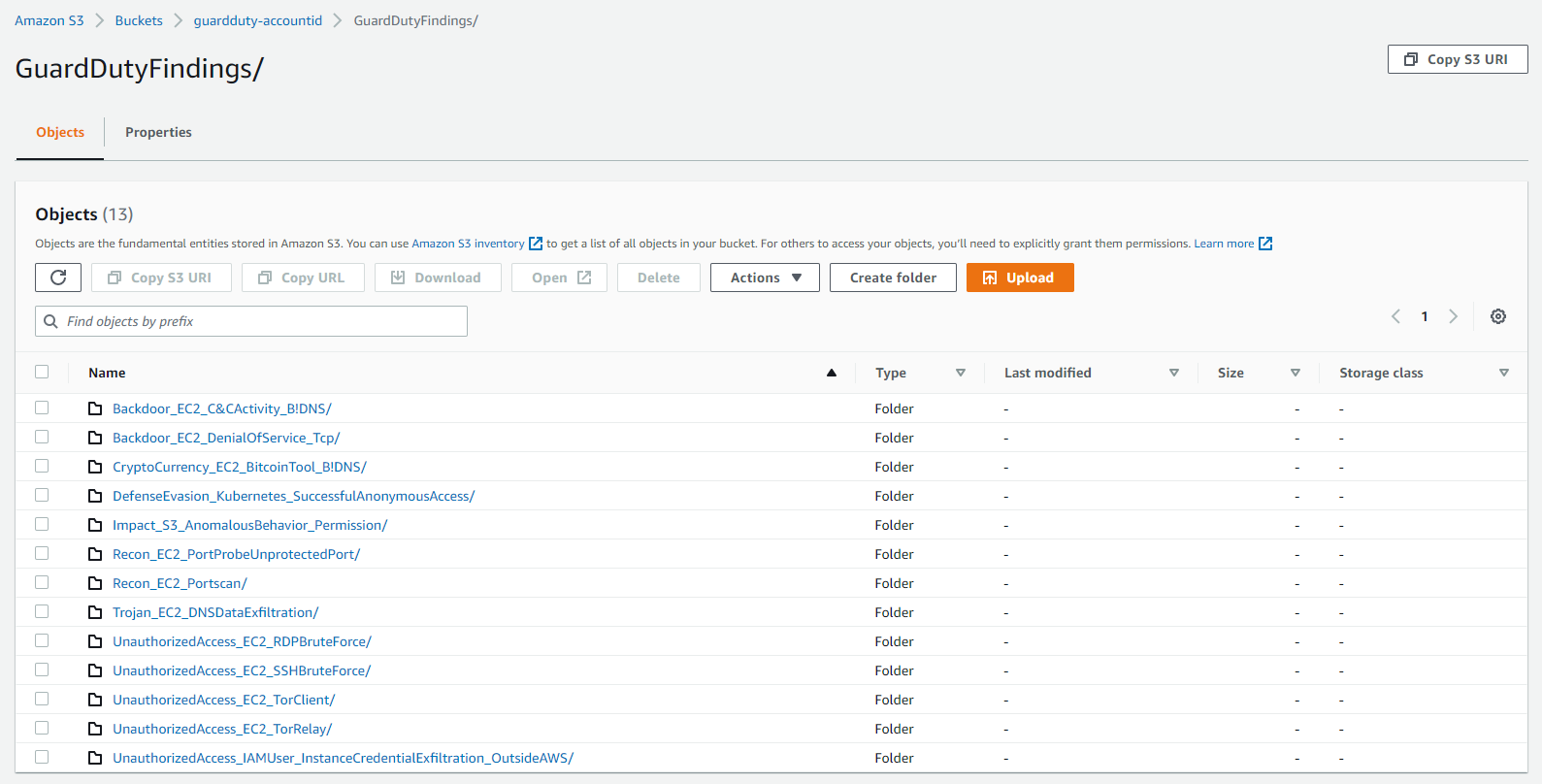
Table of Contents
🧾 Create and configure Lambda funciton
👨💻 Develop the code
📥 Import modules
🔨 Create handler function
🔎 Extract information from the S3 event
📚 Categorize S3 events
📤 Upload objects back to S3
🧾 Create and configure Lambda funciton
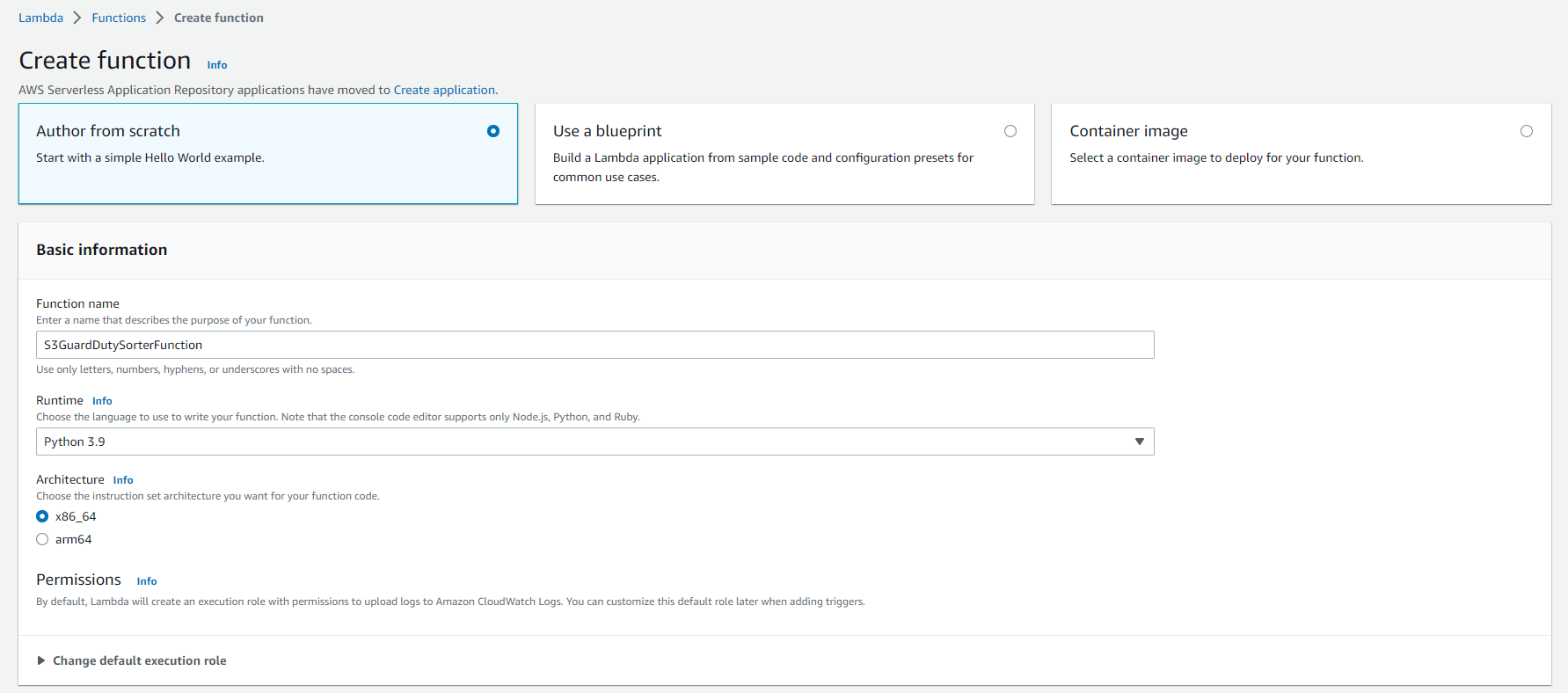
Let's start creating the lambda function first. We choose the option to author a new function from scratch and use Python 3.9 as our runtime.
Afterward, we add a trigger to the function and choose our S3 bucket. In this case, I take the GuardDuty S3 bucket.
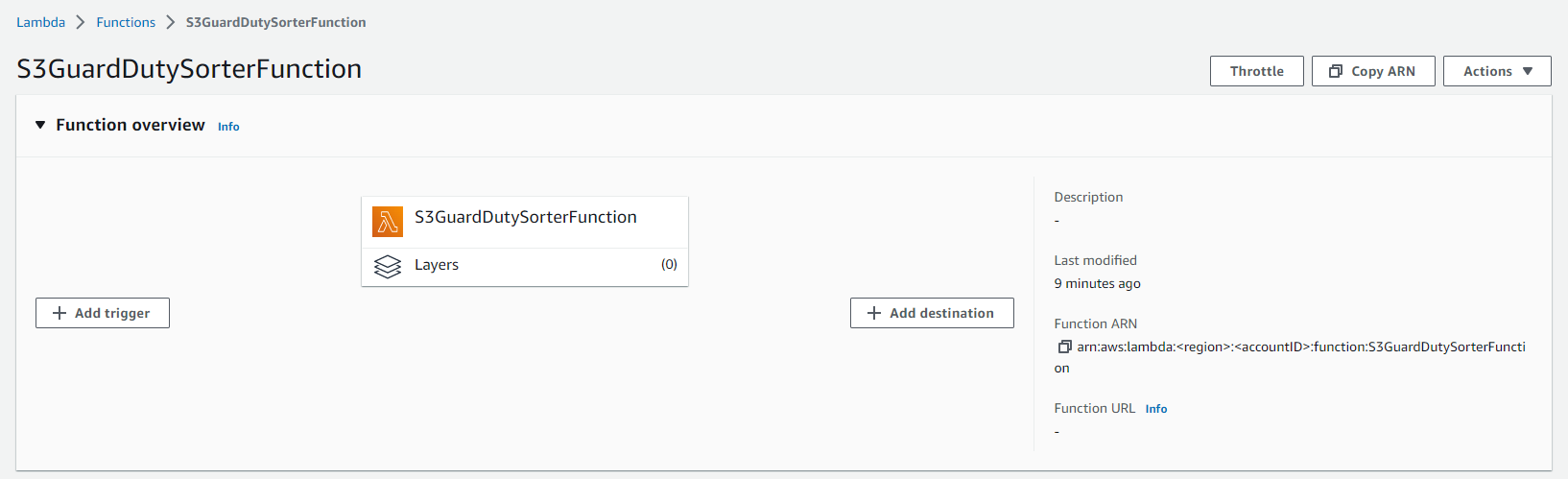
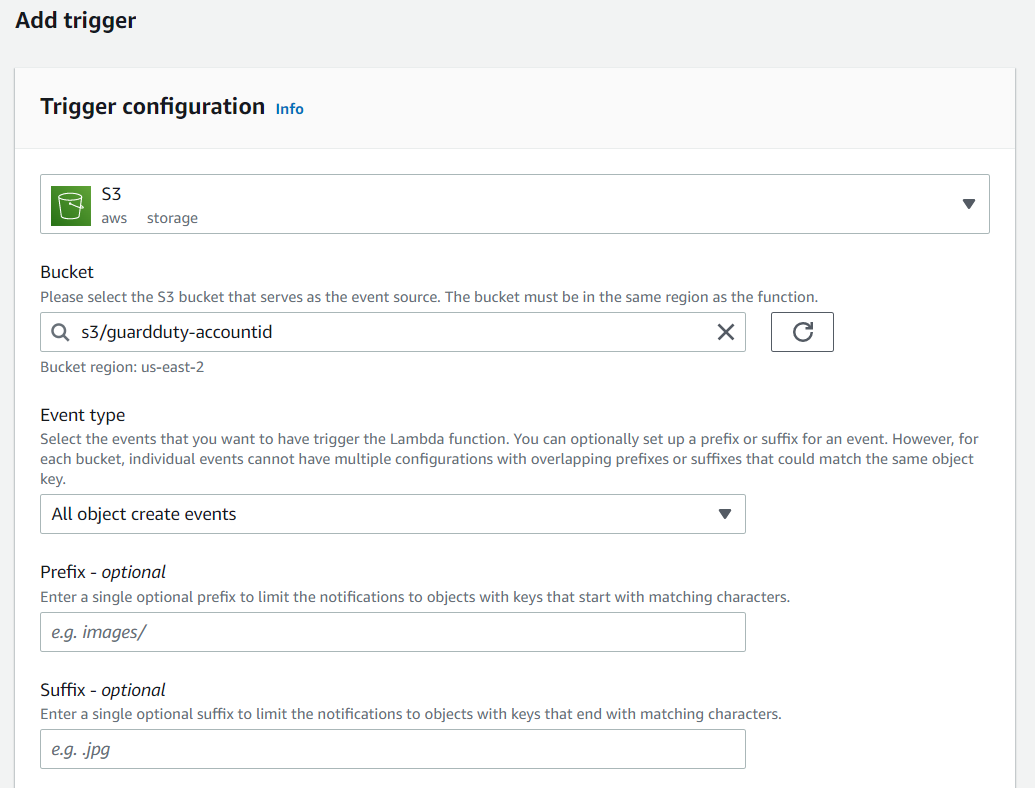
Creating the new function we can see the Runtime settings at the bottom of the page. There we can see the assigned Handler. The handler is the method that is invoked when the lambda function is triggered.

The value of the handler is the file name and the name of the handler module, separated by a dot. For example, lambda_function.lambda_handler calls the lambda_handler function defined in lambda_function.py.
👨💻 Develop the code
Now we have understood how to trigger a lambda function and where our starting point is. Let's start developing our code. We can use the integrated code editor for that. First, remove all existing code and start from a blank canvas.

Join our community of cloud security professionals. 🔐
Subscribe to our newsletter📥 Import modules
First, we need to import the necessary modules. As we want to work with data in S3, we need to add boto3 and create a new boto3 client and resource for s3. We use the boto3.client to download existing objects uploaded to S3. And we use the boto3.resource for re-uploading the data after the transformation.
import json
import boto3
import re
s3Client = boto3.client('s3')
s3Resource = boto3.resource('s3')🔨 Create handler function
As we have created an S3 trigger, our lambda function is invoked for each uploaded object to S3. The lambda function is calling lambda_handler once a new object is uploaded to S3. So let's define a new handler function.
def lambda_handler(event, context):The first argument of the function is the event object. An event object is a JSON-formatted document that contains data from the service triggering the lambda function. The second argument is the context object. The context object provides information about the invocation, function, and execution environment. In the case of an uploaded object to S3, the event object looks like this:
{
"Records": [
{
"eventVersion": "2.0",
"eventSource": "aws:s3",
"awsRegion": "us-east-1",
"eventTime": "1970-01-01T00:00:00.000Z",
"eventName": "ObjectCreated:Put",
"userIdentity": {
"principalId": "EXAMPLE"
},
"requestParameters": {
"sourceIPAddress": "127.0.0.1"
},
"responseElements": {
"x-amz-request-id": "EXAMPLE123456789",
"x-amz-id-2": "EXAMPLE123/5678abcdefghijklambdaisawesome/mnopqrstuvwxyzABCDEFGH"
},
"s3": {
"s3SchemaVersion": "1.0",
"configurationId": "testConfigRule",
"bucket": {
"name": "example-bucket",
"ownerIdentity": {
"principalId": "EXAMPLE"
},
"arn": "arn:aws:s3:::example-bucket"
},
"object": {
"key": "test%2Fkey",
"size": 1024,
"eTag": "0123456789abcdef0123456789abcdef",
"sequencer": "0A1B2C3D4E5F678901"
}
}
}
]
}Each uploaded object to S3 is defined in the Records array of the JSON object. The array can consist of several different objects, in our case GuardDuty alerts.
🔎 Extract information from the S3 event
The next part of our code is to iterate over all records from the event.
for event in event['Records']:Each record is a separate event. Going through the information of the uploaded data, the s3 JSON object is the most important.
"s3": {
"s3SchemaVersion": "1.0",
"configurationId": "testConfigRule",
"bucket": {
"name": "example-bucket",
"ownerIdentity": {
"principalId": "EXAMPLE"
},
"arn": "arn:aws:s3:::example-bucket"
},
"object": {
"key": "test%2Fkey",
"size": 1024,
"eTag": "0123456789abcdef0123456789abcdef",
"sequencer": "0A1B2C3D4E5F678901"
}
}Here we have information about the bucket name, ARN, and key. This way we can construct the exact location and filename of the uploaded object. For further processing of the data, we create variables with all S3 information:
bucketName = event['s3']['bucket']['name']
objectName = event['s3']['object']['key']
fileName = event['s3']['object']['key'].split('/')[-1]
dir = event['s3']['object']['key'].split('/')[0]
date = '/'.join(objectName.split('/')[0:4])I recommend uploading the events to a new folder. And excluding the folder from the transformation. Otherwise, we will end up in an infinite loop. We can extract the exact folder location of the uploaded object from the event object. Afterward, we check if it is the same as our destination folder:
if dir == 'GuardDutyFindings':
continueOtherwise, we can download the file from S3:
response = s3Client.get_object(Bucket=bucketName, Key=objectName)We transform the GuardDuty alert to a readable JSON format for our module. The original JSON document is newline delimited. We are replacing the newlines with commas and encapsulating them with square brackets. This way we can use the json.loads() function.
#Get all findings and transform to JSON
findings = '[' + response['Body'].read().decode('utf-8').replace('}{','},\n{') + ']'
findingsList = json.loads(findings)📚 Categorize S3 events
Next, we are iterating over all alerts which we load to the findingsList variable. We categorize all alerts by the type attribute. An example of a type is CryptoCurrency:EC2/BitcoinTool.B!DNS.
typeList = {}
#Iterate over all findings and categorize them by type
for finding in findingsList:
if finding['type'] not in typeList:
typeList[finding['type']] = []
typeList[finding['type']].append(finding)The new typeList will have the following structure:
{
"CryptoCurrency:EC2/BitcoinTool.B!DNS":[
{
"schemaVersion":"2.0",
...
"description":"EC2 instance is querying a domain name that is associated with Bitcoin-related activity."
}
]
}📤 Upload objects back to S3
The last step is to upload the alerts back to the S3 bucket. But with a new folder structure. We need to iterate over the typeList and start uploading each alert. In the path name, we need to make sure that we are only using allowed special characters. I have added a regular expression that removes most forbidden characters. And saves them in the variable findingTypeEscaped. We can then construct the new s3BucketPath. S3 creates new folders for every / we are using in the path variable.
for findingType in typeList:
print("Uploading: " + findingType)
findingTypeEscaped = re.sub('[\<\>\:\"\/\|\?\*\.]', '_', findingType)
body = ''
s3BucketPath = 'GuardDutyFindings/' + findingTypeEscaped + '/' + date + '/' + fileName + '.json'As S3 works best with JSON documents which are newline delimited, we are transforming it back. Then, we are using s3Resource to upload the object to S3.
for finding in typeList[findingType]:
body += json.dumps(finding) + '\n'
s3Resource.Bucket(bucketName).put_object(Key=s3BucketPath, Body=body)Now we can press the deploy button and the function is live. In this guide, we have created a lambda function that creates a readable directory structure every time a new GuardDuty alert is saved in S3. 🎉
The complete code looks like this in the end:
import json
import boto3
import re
s3Client = boto3.client('s3')
s3Resource = boto3.resource('s3')
def lambda_handler(event, context):
for event in event['Records']:
bucketName = event['s3']['bucket']['name']
objectName = event['s3']['object']['key']
fileName = event['s3']['object']['key'].split('/')[-1]
dir = event['s3']['object']['key'].split('/')[0]
if dir == 'GuardDutyFindings':
continue
date = '/'.join(objectName.split('/')[0:4])
response = s3Client.get_object(Bucket=bucketName, Key=objectName)
#Get all findings and transform to JSON
findings = '[' + response['Body'].read().decode('utf-8').replace('}{','},\n{') + ']'
findingsList = json.loads(findings)
typeList = {}
#Iterate over all findings and categorize them by type
for finding in findingsList:
if finding['type'] not in typeList:
typeList[finding['type']] = []
typeList[finding['type']].append(finding)
print(typeList)
#Iterate over all finding types
for findingType in typeList:
print("Uploading: " + findingType)
findingTypeEscaped = re.sub('[\<\>\:\"\/\|\?\*\.]', '_', findingType)
body = ''
s3BucketPath = 'GuardDutyFindings/' + findingTypeEscaped + '/' + date + '/' + fileName + '.json'
for finding in typeList[findingType]:
body += json.dumps(finding) + '\n'
s3Resource.Bucket(bucketName).put_object(Key=s3BucketPath, Body=body)





Member discussion